
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2020-05-29 来源:黑马程序员 浏览量:
Spark Streaming是构建在Spark上的实时计算框架,且是对Spark Core API的一个扩展,它能够实现对流数据进行实时处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming具有如下显著特点。
(1)易用性。
Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序求照的器。
(2)容错性。
Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。首先要明确一下Spak中RDD的容错机制,即每一个RDD都是个不可变的分布式可重算的数据集,它记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都可以使用原始输入数据经过转换操作重新计算得到。
(3)易整合性。
Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
Spark Streaming工作原理
Spark Streaming支持从多种数据源获取数据,包括 Kafka、Flume、Twitter、LeroMQ、Kinesis以及TCP Sockets数据源。当Spark Streaming从数据源获取数据之后,可以使用如map、 reduce、join和 window等高级函数进行复杂的计算处理,最后将处理的结果存储到分布式文件系统、数据库中,最终利用实时web仪表板进行展示。Spark Streaming支持的输入、输出源如下图所示。
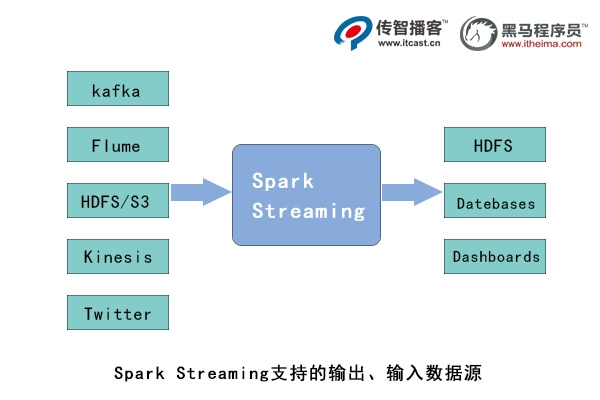
在上图中,Spark Streaming先接收实时输入的数据流,并且将数据按照一定的时间间隔分成一批批的数据,每一段数据都转变成Spark中的RDD,接着交由Spark引擎进行处理,最后将处理结果数据输出到外部储存系统。

猜你喜欢:




















.jpg)